정말 다양한 도구들로 최종 결과를 받기전 AI 파이프라인을 통한 프로세스의 복잡성을 보면 현재 '컨텍스트'를 어떻게 구성하고 최적화해서 처리할 것인지가 제일 큰 관건.
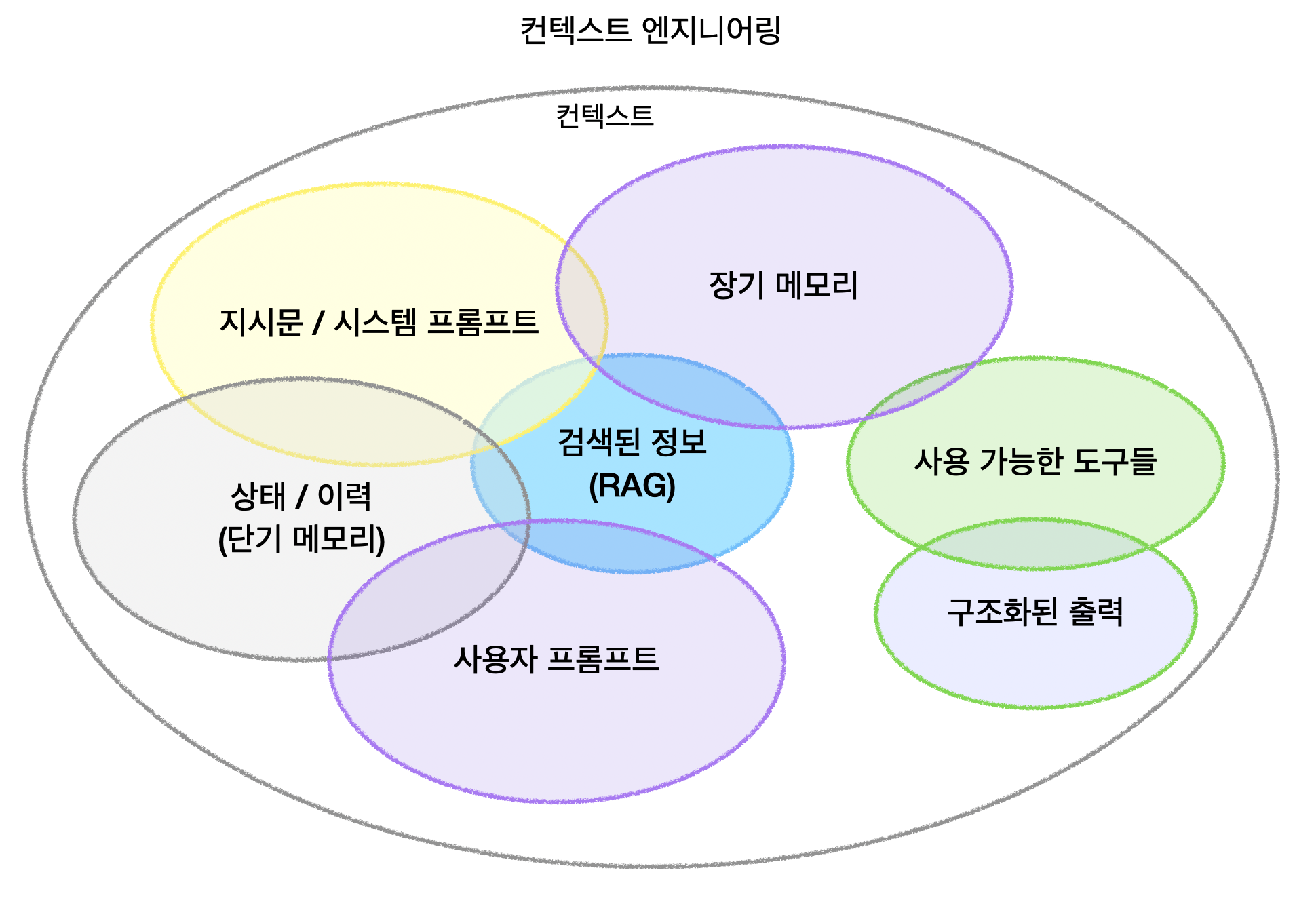
프롬프트 엔지니어링에서 컨텍스트 엔지니어링으로 | 요즘IT
컨텍스트 엔지니어링(Context Engineering)은 AI 세계에서 핫이슈로 새롭게 떠오른 용어이다. 그 등장과 함께 담론의 초점이 ‘프롬프트 엔지니어링’에서 더 넓고 강력한 개념인 ‘컨텍스트 엔지니어링’으로 이동하고 있다. 토비 루트케는…



LLM 파인튜닝과 서빙에 최적화된 개발자 플랫폼 서비스 Predibase 입니다. LoRA 파인튜닝 모델을 빠르게 학습시키고, 서비스에 적용할 때 쓰면 딱 좋을듯.

Predibase: The Developers Platform for Fine-tuning and Serving LLMs
Customize and serve open-source models for your use case that outperform GPT-4—all within your cloud or ours.

와우! 제미나이 2.5 implicit caching 지원 한다고 합니다. 제미나이 2.5 API 사용하는 사람들, 기업들에게 꽤 가격인하 효과가 체감되는 곳들이 많을 것 같은 소식. 제미나이 2.5 는 이제 엄청나게 많은 곳에서 (저역시 주력 사용하게 된..) API 인데요. 워낙 Context 가 크니까 캐싱 효과가 상당할텐데.. 이걸 이제 암묵적으로 지원해준다고!! 원래도 저렴했는데 더 굳..

Gemini 2.5 Models now support implicit caching
Explore implicit caching – now supported in Gemini 2.5 – bringing automatic cost savings to developers using the Gemini API.
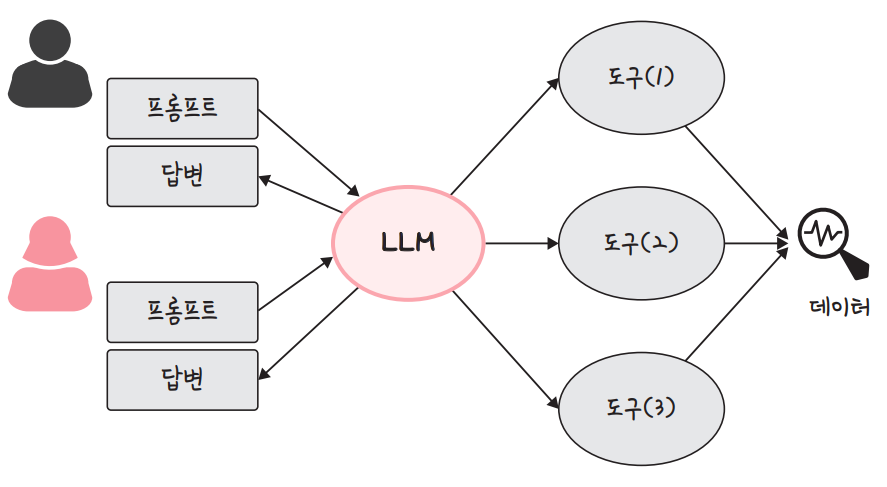
다중 에이전트 시스템, 왜 아직 크게 성능향상이 기대보다 못할까. 라는 주제의 2025.03월 논문입니다. 지금 각광받고 관련 프레임워크는 쏟아지지만, 오히려 fail 되는 경우가 많다고도. 크게 시스템 설계 실패, 에이전트 간 정렬 불량, 검증 및 종료 등으로 구분된다고 하네요. 연구에서 사용된 MAS 로는 대표적인 MAS 5가지 (MetaGPT, ChatDev, HyperAgent, AppWorld, AG2) 가 사용되었습니다. LLM 은 GPT-4o 또는 Claude 3 를 사용했다고 하구요. 150여개 Task 로 테스트 했습니다. 논문상 Fail Rate 가 제일 낮은것은 AG2 (15.2%), 그다음은 MetaGPT (34%) 였고 나머지 3개는 70% 이상 Fail 이었습니다.

Paper page - Why Do Multi-Agent LLM Systems Fail?
Papers arxiv:2503.13657 Why Do Multi-Agent LLM Systems Fail? Published on Mar 17 · Submitted by philschmid on Mar 21 Authors: Mert Cemri…
정말 작은데 멀티모달에 function calling 에.. 여러모로 넘 좋네요.

OpenRouter는 다양한 LLM 을 직접 API 로 호출하지 않고 하나의 API 로 호출하면서도 해당 프롬프트에 가장 최적화된 API 로 최적화된 라우팅 을 하면서 비용 효율적인 LLM 호출을 제공하는 서비스 입니다. API Key 하나로 여러 모델을 편하게 쓸 수 있는건 덤. (어떤 LLM 모델로 호출하게 될지 상세 옵션 등으로 어느정도 제한 도 가능. 그리고 사용한 만큼 과금이므로 굳이 비싼 요금제 가입 필요 없음.) 여기에 더해 사실 같은 API 라도 (예를 들어 closed 인 Claude 모델이더라도) 여기저기서 서비스하는데요 (Anthropic 공식, Amazon Bedrock, Google Vertex) 어디가 지금 서버 상태가 쾌적한지 알아서 보고 라우팅 해줍니다. 개인이 api 쓰면 rate limit 문제도 해결되구요. 단, 기본적으로 token 당 원래 최종 model 요금에 더해 추가 과금이 있네요. OpenRouter 에서 5% 더 과금한다고 합니다. 🥲 * 그래서 저렴한거 위주로 쓰면 좋은듯? ㅎㅎ 다양한 LLM 에 대해 한번에 프롬프트를 보내고 비교 할 수 있는 서비스도 제공합니다. OpenRouter 를 쓰지 않아도 각종 LLM 성능을 비교하기에 좋아요. 각종 필터링, 조건, 성능 가격 다 비교해 볼 수 있구요. 그리고 여기서 사용자들이 어떤 모델로 Token 을 많이 잘 사용하고 있는지를 토대로 Ranking 도 볼 수 도 있습니다! 와.. 이거 실질적인 트렌드를 한눈에 볼 수 있네요. 랭킹은 일반 랭킹 뿐 아니라 다양한 용도 (프로그래밍, 롤플레이, 마케팅, SEO, Tech, 번역, 법, 금융, 헬스, 아카데이, Trivia) 별 랭킹도 볼 수 있고 기간 별로 (오늘, 이번 주, 이번달, 트렌딩) 살펴볼 수 있구요. LLM 여러개 비교해서 쓸 때 여기서 먼저 보는걸 추천!…
OpenRouter
A unified interface for LLMs. Find the best models & prices for your prompts
앤트로픽 연구원들이 공유해주는 AI 에이전트 개발 팁! 우선 AI Agent 를 도입했을 때 효과적인 일의 종류, 그 이전에 AI Agent 가 일반적인 워크플로우 지정과 어떻게 다른지 그 의미를 먼저 잘 파악하길 권장했어요. 워크플로우와 달리 AI 에이전트는 제어하기 어려운 부분도 있으므로 오류 비용은 상대적으로 낮으면서 복잡한 작업에 어울린다고 합니다. 특히 검색엔진에서 도움이 많이 된다고 하구요. 2025년에는 에이전트가 비즈니스 전반에 채택되면서 반복적인 작업을 자동화할 수 있을 것이라고 기대하구요. 하지만 소비자를 위한 쇼핑 도우미 와 같은 용도로는 여전히 사용이 어렵고 비싸서 기대치를 낮춰야 할 것 같습니다. 구축을 위한 팁. 결과를 측정할 수 있는 방법을 마련해야 한다. 성공적인 피드백을 줄 수 있도록 단순하게 시작해야 한다고.

딥시크 사태로 계속 화제가 되는 최신 모델 증류 방식. $50 달러 라고 하니 확실히 쉽게 더 화제가 되는 듯...

스탠포드·워싱턴대 "50달러로 추론 모델 구축...'증류' 방식 적용"
딥시크 등장 이후 저렴한 비용으로 추론 모델을 구축했다는 연구가 이어지는 가운데, 이번에는 50달러(약 7만2800원)로 추론 모델을 훈련했다는 모델이 등장했다. 모델 '증류'에 사용하는 데이터를 선별해 학습 비용을 크게 줄였으며, 모델의 생각하…
스탠포드 워싱턴 대에서 $50 로 최신 모델 수준의 성능을 달성할 수 있다고 화제가 되고 있길래 확인해본 소스. 테스트 타임 스케일링 증류 기법을 소개한 논문 오픈소스 입니다. 정말 가볍게 최신 모델 수준을 모사하기에 매우 좋은 방법 같아 보이네요? * 물론 $50 는 과장된 부분이 있습니다.. Base 로 쓰인 오픈웨이트 모델인 Qwen2.5-32B 자체가 워낙 좋은 모델이니까요. 논문: https://arxiv.org/pdf/2501.19393 소스: https://github.com/simplescaling/s1
GitHub - simplescaling/s1: s1: Simple test-time scaling
s1: Simple test-time scaling. Contribute to simplescaling/s1 development by creating an account on GitHub.
![[이스트소프트] AI 모델 개발자 양성과정](http://img2.dbcart.net/fileupload_folder/landing_top_35082_1736999976_0_25135514.png)
젠스파크의 놀라운 기능 Mixture-of-Agents (MOA) 에 대한 소개 영상이 나왔어요. OpenAI, Anthropic, Gemini 등 여러 모델에 응답을 한번에 받고. 각 모델별 장점을 합쳐줍니다. 완전 놀라움!